
| Tasty byte-size provocations to refuel your thinking! | Brought to you by: |
Integrating Online Music Databases: The LinkedMusic Project
Advancements in digital technology have made online text searches seamless, enabling scholars to tackle complex research questions with ease. Searching for musical information online, however, remains a significant challenge. Despite the vast amount of music-related data available on the internet, researchers struggle to perform large-scale searches due to the fragmented nature of music databases and the diversity of musical formats—scores, recordings, and images.
Hundreds of specialized music databases exist, each offering valuable metadata and content. Yet, these databases use different systems to organize data, making it difficult for researchers to connect information across platforms. For example, identifying links between performers, composers, or scores often requires navigating multiple platforms (e.g., Oxford Music Online, Music Index, and IMSLP), each with its own structure and limitations. This lack of integration severely restricts the potential for large-scale, interconnected music research.
The LinkedMusic Partnership addresses this challenge by creating a global digital music library that unifies access to these diverse databases. To achieve this, we are using linked data principles, which allow computers to recognize relationships between concepts like composers and works, by assigning them unique identifiers. This ensures that information from different databases can be connected seamlessly, even if the terminology or structure differs. Instead of relying on ambiguous keyword searches, linked data assigns unique identifiers to entities like “Handel” or “Messiah,” ensuring accurate and consistent connections across different databases.
At the heart of this project is Search Engine System for Enhancing Music Metadata Interoperability (SESEMMI), an open-source metasearch engine that enables users to search across multiple databases simultaneously and connect back to the original sources. SESEMMI is not just a search engine; it is a transformative tool for unifying and enhancing global music research by making vast, fragmented databases interoperable and accessible through advanced technology.
Artificial Intelligence plays a key role in making SESEMMI accessible. Tools like ChatGPT enable users to ask questions in everyday language, eliminating the need for technical expertise. For instance, a user could simply type, “Find 19th-century French composers born in Paris,” and the AI will translate the question into the necessary technical query behind the scenes. Additionally, AI’s multilingual capabilities will enable searches in various languages, making the platform truly global and inclusive.
This combination of linked data principles and AI technology will transform music research. By supporting large-scale, multilingual, and cross-database searches, researchers will be able to explore previously unanswerable questions. For instance, they could track the global spread of genres like K-pop or document Indigenous music cultures, all while drawing connections between diverse databases.
Funded by Canadian and Quebec government agencies, this ambitious seven-year project brings together major music libraries (e.g., Bavarian State Library, British Library), international organizations (RISM), and leading databases (e.g., MusicBrainz, Cantus Database, DIAMM). Together, the LinkedMusic Partnership will lay the foundation for a more interconnected, inclusive, and accessible future for music scholarship.
Previous Work
A parallel project in the field of visual art, known as Linked Art, involves prominent institutions like the Louvre, Rijksmuseum, Metropolitan Museum of Art, Museum of Modern Art, and the Victoria and Albert Museum. The Linked Art Editorial Board includes members from the Canadian Heritage Information Network, Europeana,1 and Oxford University. We plan to consult their conceptual model and adopt their general principles, including the design goals of Linked Open Usable Data (LOUD).
The challenge of connecting databases spans many fields, including genomics and large corporations. In music research, earlier initiatives like the Sheet Music Consortium (SMC) and Doing Reusable Musical Data (DOREMUS) have tackled similar issues by interlinking collections, though their scope was narrower or focused on specific types of metadata. One solution, used by the Europeana consortium, involves converting metadata into a standardized format for all members. However, this strategy relies on significant resources, making it impractical for many smaller music databases. LinkedMusic takes a unique approach by leveraging linked data principles to connect databases flexibly, avoiding the need for costly standardization and making participation feasible even for smaller database providers.
Our approach is inspired by the idea of making online resources more connected and accessible. Keyword searches can lead to ambiguous results—such as “Schumann” returning mixed data on both Robert and Clara Schumann. LinkedMusic eliminates this issue by assigning distinct identifiers to each concept, ensuring that researchers find precise and accurate results, even when working across multiple databases. By focusing on linking resources in a way that computers can easily interpret, we can overcome many of the barriers to integrating these diverse collections.
Methodology
Our approach begins by requesting a complete data export from each music database, such as a database file or a spreadsheet. We process this data independently, preserving each database’s unique structure and avoiding the need for standardized metadata across all sources. Instead, differences in metadata are addressed during the search process.
SESEMMI integrates music databases by assigning unique identifiers to concepts like names, places, and instruments, ensuring consistency across variations (e.g., different spellings of Tchaikovsky). It also enriches metadata with external resources like Wikidata, adding valuable details, such as composer biographies and demographic attributes (e.g., gender or ethnicity). We address internationalization not just through translation but by respecting cultural differences in concepts like “composer” or “performer.” For instance, roles in non-Western music traditions may not align with standard Western categories, and SESEMMI ensures these nuances are preserved. Rather than forcing categories into a single definition, we link related ideas, allowing users to explore relationships across cultural contexts. This global, culturally sensitive perspective supports new avenues of research that were previously out of reach.
Current Workflow
We are currently working to transform the metadata from each music database into a format that makes it easier to link and search across different collections. To do this, using a tool called OpenRefine, we link names, places, and other details to reference systems like Wikidata, unifying concept variations (e.g., differences in spelling) under a single identifier. The data is then stored in a graph database,2 designed for efficient linking and searching. See figure 1 for the overall process. While much of the process is automated, we develop custom scripts for each database, enabling re-imports whenever updates are needed.
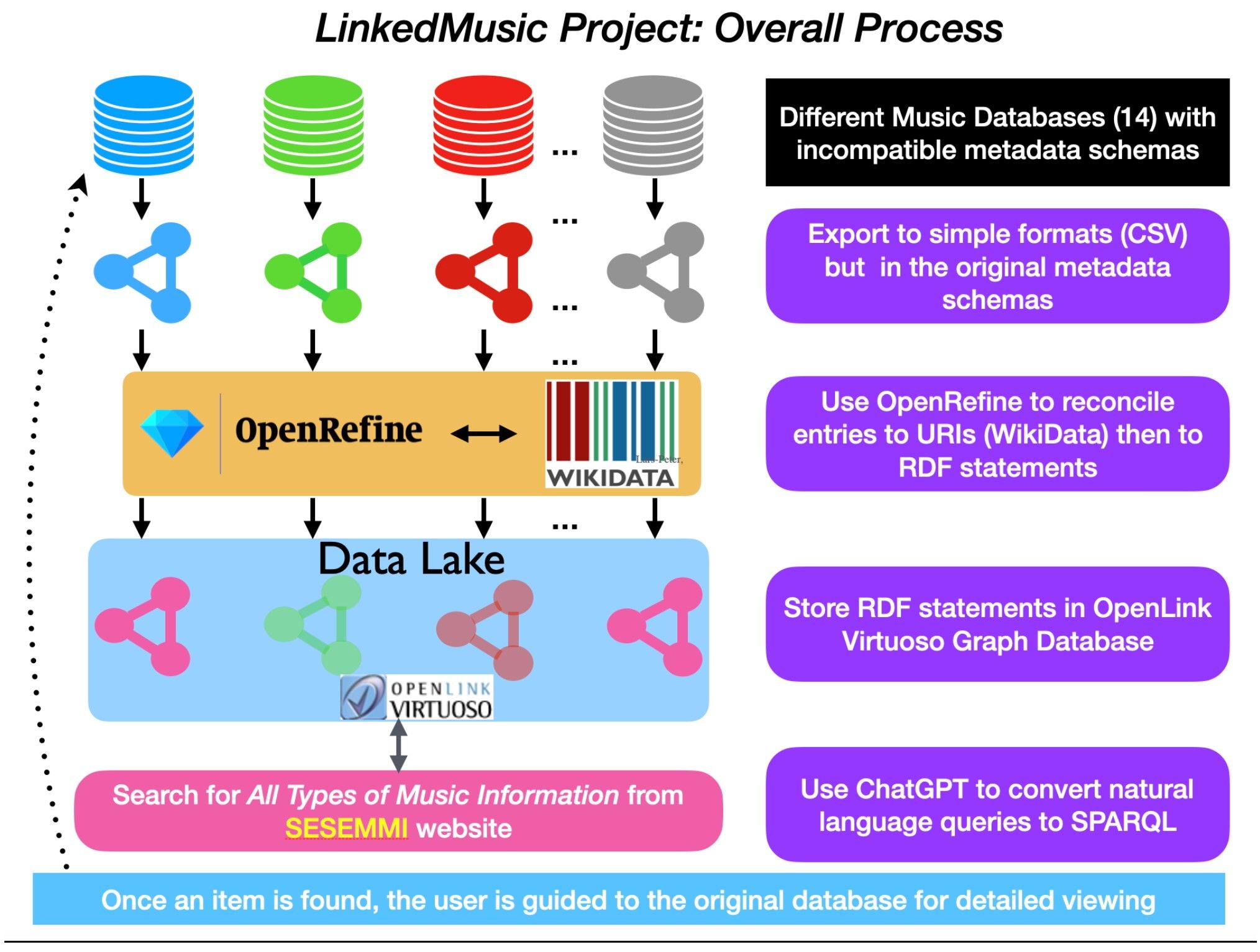
SESEMMI makes this data accessible through a user-friendly interface. Since querying a graph database typically requires specialized technical knowledge (e.g., SPARQL), we are integrating tools like ChatGPT to allow users to search using everyday language. For instance, a user could type, “Find recordings of Monteverdi released in Canada in the 1960s,” and the system would automatically generate the required search query.
This approach offers several key benefits:
- Expanded capabilities: Users can ask complex questions that go beyond what individual databases were originally designed to answer.
- Multilingual access: Searches can be conducted in a user’s preferred language, regardless of the database’s original language.
- Enriched data: By linking databases with external sources like Wikidata, we can incorporate additional details, such as biographical or demographic information, that may not exist in the original database.
- Cross-database insights: By connecting multiple databases, researchers can uncover patterns and relationships that would be impossible to identify by searching each database individually.
Looking ahead, advancements in AI will further simplify searching, allowing users to explore linked collections without requiring technical expertise. This innovative combination of linked data and AI-powered tools positions SESEMMI as a transformative resource for music historians, fostering more intuitive and comprehensive exploration of musical knowledge.
Conclusions
This project promises to greatly enhance access to musical resources worldwide, creating an inclusive, interconnected ecosystem for scholars, musicians, and the public. By breaking down barriers between fragmented databases, it paves the way for innovative research and deeper understanding of global musical heritage.
Our initial goal is to create a searchable network of fourteen open music databases, with plans to expand this network to include even more collections in the future. A key innovation of this project is the framework we have developed to integrate multiple metadata systems, allowing seamless searches through our metasearch engine, SESEMMI.
Importantly, our approach avoids requiring data providers to change their existing systems, making it easier for smaller databases to participate. This not only increases the visibility of these collections but also broadens access for a wider range of users, creating a more inclusive and connected musical research ecosystem.
Acknowledgments
This research has been supported by the Social Sciences and Humanities Research Council of Canada (SSHRC 895-2022-1004) and the Fonds de Recherche du Québec—Société et Culture (FRQSC SE3-303927).
